Mastering Cilium Network Policies: Zero-Trust Security for Kubernetes“Trust No One. Authenticate Everyone. Secure Everything!”3d ago3d ago
Microservices Monitoring with Grafana & Prometheus in KubernetesDeploy K8S cluster, Deploy Prometheus & Grafana, Deploy Microservices, Monitor Microservices — Life is easyMar 26Mar 26
Microservices deployment on KubernetesDeploying Flask frontend, and PostgreSQL server as backendOct 5, 20241Oct 5, 20241
Deploying custom PostgreSQL server on OpenShift/KubernetesCustom PostgreSQL server comes up with pre-initiallised database, tables, relations and more.Oct 1, 2024Oct 1, 2024
Enterprise grade software development workflow using Makefile, Dockerfile, Jenkinsfile & Pipfile…The ultimate guide setting ablaze a continous integration (CI) piplineJul 6, 2024Jul 6, 2024
Decomposing a monolithic database for microservice architectureSchema design and its application for bounded context in domain-driven developmentOct 29, 2023Oct 29, 2023
Published inDevOps.devDeep dive into Databricks delta-lakesTechnologies used: Python, PySpark, and SQL on Databricks notebooksOct 27, 20231Oct 27, 20231
Ace your SQL interviews by doing these 10 advanced queriesI have used PostgreSQL, but these queries can be used in any SQL engine. I assume you have already installed the SQL engine on your local…Oct 24, 2023Oct 24, 2023
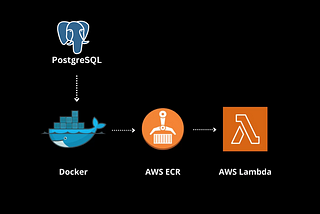
Installing Postgres-11 on Python-3.11Installing postgres11 in public.ecr.aws/lambda/python:3.11, but underlying Linux is Amazon Linux 2, so applicable for all instances using…Aug 19, 2023Aug 19, 2023
Adhere your Pandas data analytics class to the single responsibility and open close principle of…Do you impeccably organize your Panda’s methods in a class like this?Sep 9, 2022Sep 9, 2022